

NVIDIA в понедельник на конференции GTC 2024 представила графические процессоры Blackwell B200 и GB200 AI. Они разработаны, чтобы обеспечить невероятный пятикратный прирост производительности в области искусственного интеллекта по сравнению с «Hopper» H100 текущего поколения, и имеют в четыре раза больше встроенной памяти. По словам его создателей, B200 «Blackwell» — это самый большой чип, который физически возможен при использовании существующих литейных технологий. Чип состоит из 208 миллиардов транзисторов и состоит из двух чиплетов, которые сами по себе являются самыми большими из возможных чипов.
Каждый чиплет построен на литейном узле TSMC N4P, который является самым передовым узлом класса 4 нм, созданным тайваньским литейным заводом. Каждый чиплет имеет 104 миллиарда транзисторов. Два чиплета имеют высокую степень соединения друг с другом благодаря специальному межсоединению со скоростью 10 ТБ/с. Этой пропускной способности и задержки достаточно, чтобы оба могли поддерживать согласованность кэша (т. е. обращаться к памяти друг друга, как к своей собственной). Каждый из двух чипсетов Blackwell имеет 4096-битную шину памяти и подключен к 96 ГБ HBM3E, распределенным по четырем стекам по 24 ГБ; что составляет 192 ГБ для пакета B200. Графический процессор имеет ошеломляющую пропускную способность памяти — 8 ТБ/с. Пакет B200 включает интерфейс NVLink со скоростью 1,8 ТБ/с для подключения к хосту и подключения к другому чипу B200.




NVIDIA также анонсировала суперчип Grace-Blackwell GB200. Это модуль с двумя графическими процессорами B200, подключенными к процессору NVIDIA Grace, который обеспечивает более высокую производительность последовательной обработки, чем процессоры на базе x86-64 от Intel или AMD; и ISA, оптимизированная для графических процессоров NVIDIA с искусственным интеллектом. Самым большим преимуществом процессора Grace перед Intel Xeon Scalable или AMD EPYC является более высокая пропускная способность соединения NVLink с графическими процессорами по сравнению с соединениями PCIe для хостов x86-64. Похоже, что NVIDIA перенесла процессор Grace из суперчипа GH200 Grace-Hopper.




NVIDIA не раскрыла количество различных компонентов SIMD, таких как потоковые мультипроцессоры на чиплет, ядра CUDA, тензорные ядра или размеры встроенной кэш-памяти, но сделала заявления о производительности. Каждый чип B200 обеспечивает 20 Пфлопс (это 20 000 Тфлопс) производительности вывода ИИ. «Blackwell» представляет движок NVIDIA Transformer 2-го поколения и ядро Tensor 6-го поколения, которое поддерживает FP4 и FP6. Интерфейс NVLink 5-го поколения не только масштабируется внутри узла, но и масштабируется до 576 графических процессоров. Среди заявлений NVIDIA о производительности GB200 — 20 PFLOP FP4 Tensor (плотный) и 40 PFLOP FP4 Tensor (разреженный); 10 PFLOPs FP8 Тензор (плотный); и тензор FP8 20 PFLOP (разреженный); 5 PFLOP Bfloat16 и FP16 (10 PFLOP с разреженностью); и 2,5 PFLOP TF32 Tensor (плотный) с 5 PFLOP (разреженный). В качестве высокоточного ускорителя вычислений (FP64) B200 обеспечивает производительность 90 терафлопс, что в 3 раза больше, чем у GH200 «Hopper».
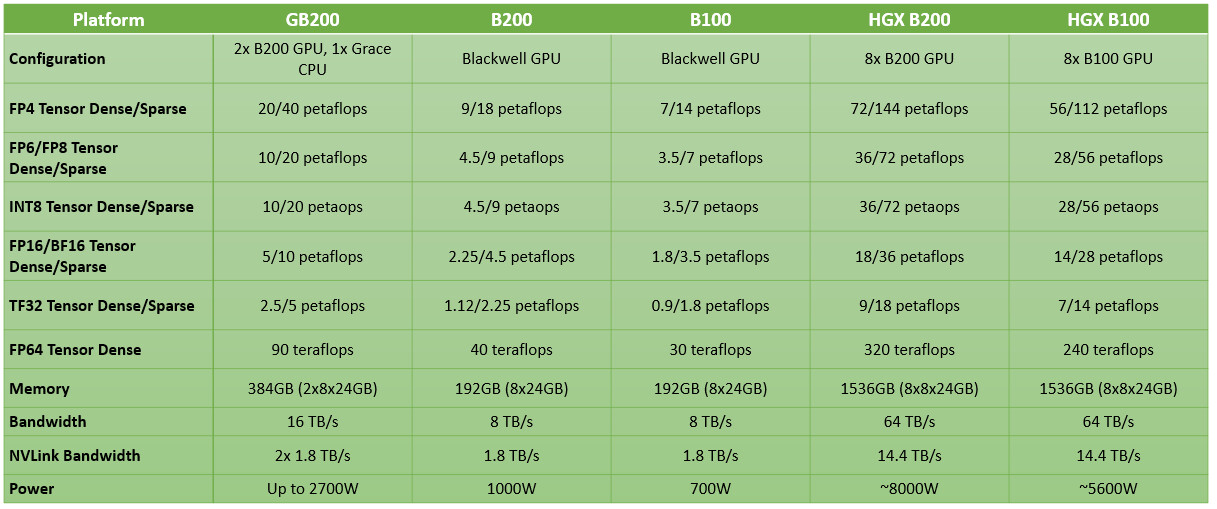
Ожидается, что NVIDIA поставит B100, B200 и GB200, а также их производные, такие как SuperPOD, позднее в этом году.


0 Комментариев