

Графические процессоры отходят на второй план, поскольку Intel делает ставку на Гауди в области искусственного интеллекта.
Сегодня Intel сделала множество объявлений во время своего мероприятия Vision 2024, включая подробные сведения о своих новых процессорах Gaudi 3 AI, которые, по ее утверждению, обеспечивают до 1,7 раз большую производительность обучения, на 50 % лучший вывод и на 40 % лучшую эффективность, чем у Nvidia. лидирующие на рынке процессоры H100, но за значительно меньшие деньги. Intel также объявила о новом брендинге своего портфеля процессоров для центров обработки данных: чипы Granite Rapids и Sierra Forest теперь называются новым семейством Xeon 6. Эти чипы должны выйти на рынок в этом году и добавить поддержку нового стандартизированного формата данных MXFP4, повышающего производительность.
Intel также объявила, что разрабатывает ASIC AI NIC для сетей, совместимых с Консорциумом Ultra Ethernet, и чиплет AI NIC, который будет использоваться в ее будущих процессорах XPU и Gaudi 3, а также будет доступен внешним клиентам через Intel Foundry , но это не Не буду делиться более подробной информацией об этих сетевых продуктах.
Доминирование Nvidia в инфраструктуре искусственного интеллекта и программном обеспечении неоспоримо. Тем не менее, Intel, как и AMD, стремится занять позицию главной альтернативы Nvidia, поскольку отрасль продолжает бороться с острой нехваткой графических процессоров Nvidia для искусственного интеллекта . С этой целью Intel также представила полный спектр своих программ поддержки искусственного интеллекта, которые простираются от аппаратного обеспечения до программного обеспечения, поскольку она надеется завоевать популярность на быстро развивающемся рынке искусственного интеллекта, на котором в настоящее время доминируют Nvidia и AMD. Усилия Intel сосредоточены на развитии партнерской экосистемы для предоставления полноценных систем Gaudi 3, а также на работе над созданием открытого стека корпоративного программного обеспечения, который станет альтернативой собственной CUDA от Nvidia.
Intel предоставила подробную информацию об архитектуре Gaudi 3, а также множество убедительных тестов по сравнению с существующими графическими процессорами Nvidia H100 (данные для будущих систем Blackwell пока недоступны). Для начала давайте поближе познакомимся с архитектурой Гауди 3.
Технические характеристики Intel Гауди 3
Intel Gaudi 3 представляет собой третье поколение ускорителя Гауди, ставшего результатом приобретения Intel компании Habana Labs за 2 миллиарда долларов в 2019 году . Ускорители Гауди начнут массовое производство и станут общедоступными в третьем квартале 2024 года в OEM-системах. Intel также сделает системы Gaudi 3 доступными в своем облаке для разработчиков, тем самым предоставив потенциальным клиентам быстрый доступ к тестированию чипов.








Gaudi выпускается в двух форм-факторах: OAM (OCP Accelerator Module) HL-325L является распространенным мезонинным форм-фактором, встречающимся в высокопроизводительных системах на базе графического процессора. Этот ускоритель имеет 128 ГБ HBM2e ( не HBM3E), обеспечивая пропускную способность 3,7 ТБ/с. Он также имеет двадцать четыре сетевых адаптера RDMA Ethernet 200 Гбит/с. Модуль OAM HL-325L имеет TDP 900 Вт (возможны и более высокие TDP, якобы с жидкостным охлаждением) и рассчитан на производительность FP8 1835 терафлопс. OAM развертываются группами по восемь на каждый серверный узел, а затем могут масштабироваться до 1024 узлов.
Intel утверждает, что Gaudi 3 обеспечивает вдвое большую производительность FP8 и в четыре раза большую производительность BF16, чем предыдущее поколение, а также вдвое большую пропускную способность сети и в 1,5 раза большую пропускную способность памяти.
Модули OAM устанавливаются на универсальную базовую плату, на которой размещено восемь модулей OAM. Intel уже отправила OAM и материнские платы своим партнерам, готовясь к общедоступной продаже позднее в этом году. Масштабирование до восьми модулей OAM на базовой плате HLB-325 повышает производительность до 14,6 Пфлопс по сравнению с FP8, в то время как все остальные показатели, такие как объем памяти и пропускная способность, масштабируются линейно.
У Intel также есть двухслотовая карта расширения Gaudi 3 PCIe с TDP 600 Вт. Эта карта также имеет 128 ГБ HBMeE и двадцать четыре сетевых адаптера Ethernet 200 Гбит/с — Intel заявляет, что для горизонтального масштабирования используются два сетевых адаптера 400 Гбит/с. Intel заявляет, что карта PCIe имеет такую же пиковую производительность FP8 в 1835 терафлопс, что и OAM, что интересно, учитывая более низкий TDP на 300 Вт (это, вероятно, не будет сохраняться при длительных рабочих нагрузках). Однако масштабирование внутри коробки более ограничено, поскольку оно предназначено для работы группами по четыре человека. Intel заявляет, что эта карта также может масштабироваться для создания более крупных кластеров, но не предоставила подробностей.
Dell , HPE, Lenovo и Supermicro предоставят системы для запуска Gaudi 3. Модели Gaudi с воздушным охлаждением уже были отобраны, а образцы моделей с жидкостным охлаждением появятся во втором квартале. Они станут общедоступными (массовое производство) в третьем и четвертом кварталах 2024 года соответственно. Карта PCIe также будет доступна в четвертом квартале.
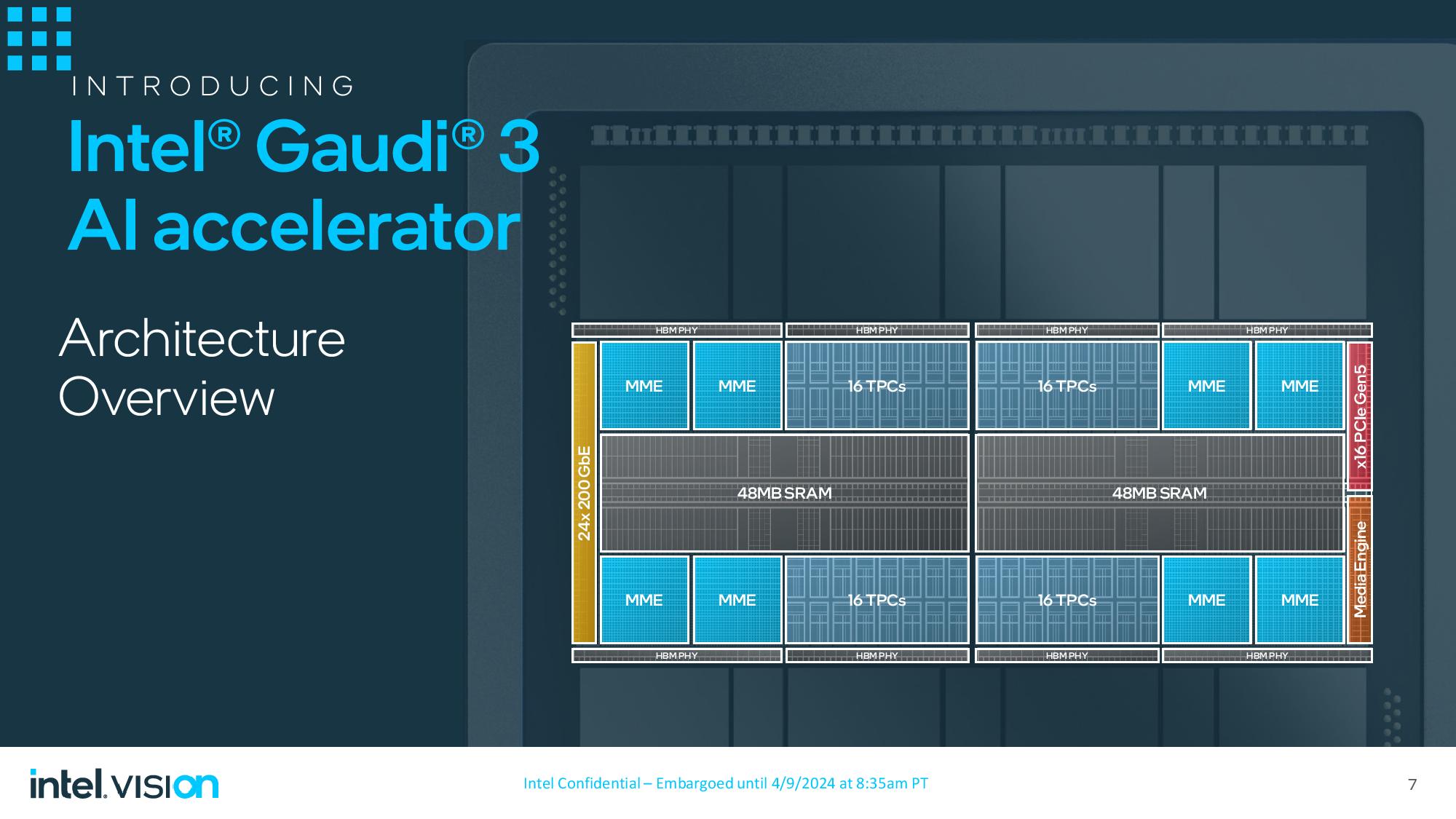
Gaudi 3 использует ту же архитектуру и базовые фундаментальные принципы, что и его предшественник, но использует более совершенный 5-нм техпроцесс TSMC, чем 7-нм узел TSMC, который Intel использует для ускорителя Gaudi 2.
Конструкция OAM состоит из двух центральных 5-нм кристаллов с разделенной между ними 96 МБ SRAM, обеспечивающей пропускную способность 12,8 ТБ/с. Между кристаллами установлены восемь пакетов HBM2E общей емкостью 128 ГБ, которые обеспечивают пропускную способность до 3,7 ТБ/с. Соединение с высокой пропускной способностью между двумя кристаллами обеспечивает доступ ко всей памяти, присутствующей на обоих кристаллах, что позволяет ему выглядеть и действовать как единое устройство (по крайней мере, что касается программного обеспечения — задержка может варьироваться). Gaudi 3 также имеет контроллер x16 PCIe 5.0 для связи с главным процессором (ЦП), и можно использовать различные соотношения ЦП и ускорителей Gaudi.
Вычисления обрабатываются 64 ядрами тензорной обработки пятого поколения (TPC) и восемью матричными математическими механизмами (MME), при этом рабочие нагрузки распределяются между двумя ядрами с помощью компилятора графов и программного стека. Пакет микросхем Gaudi 3 также включает в себя двадцать четыре Ethernet-контроллера RoCE со скоростью 200 Гбит/с, которые обеспечивают как масштабируемое (внутреннее), так и масштабируемое (между узлами) соединение, что вдвое увеличивает количество соединений со скоростью 100 Гбит/с в Gaudi 2.
Гауди 3 Масштабируемость

В конце концов, ключ к доминированию в современных рабочих нагрузках по обучению ИИ и выводам лежит в возможности масштабировать ускорители в более крупные кластеры. Intel Gaudi использует другой подход, чем будущие системы Nvidia B200 NVL72 , используя быстрые Ethernet-соединения со скоростью 200 Гбит/с между ускорителями Gaudi 3 и объединяя серверы с конечными и магистральными коммутаторами для создания кластеров.
Архитектура системного уровня Nvidia использует NVLink через интерфейс PCIe как для встроенного подключения между графическими процессорами, так и для расширения для подключения целых стоек с помощью пассивных медных кабелей через коммутаторы NVLink. У AMD также есть собственный подход к использованию интерфейса PCIe и протокола Infinity Fabric между графическими процессорами, находящимися на сервере, при использовании внешних сетевых карт для связи с другими узлами, но это увеличивает стоимость и сложность сети, чем подход Intel, включающий встроенные сетевые карты непосредственно в чип.
Благодаря удвоенной пропускной способности сети Gaudi 3 масштабируется от одного узла с 8 OAM Gaudi до кластеров, содержащих до 1024 узлов (серверов), вмещающих 8192 устройства OAM.
Каждый сервер состоит из восьми ускорителей Gaudi 3, взаимодействующих друг с другом через двадцать одно соединение Ethernet 200 Гбит/с каждый. Остальные три порта Ethernet на каждом устройстве используются для внешней связи с кластером через листовой коммутатор. Коммутатор объединяет эти соединения в шесть портов Ethernet 800 Гбит/с с разъемами OFSP для облегчения связи с другими узлами.
Каждая стойка обычно содержит четыре узла, но это число может варьироваться в зависимости от ограничений мощности стойки и размера кластера. До 16 узлов образуют один подкластер с тремя конечными коммутаторами Ethernet, которые затем подключаются к магистральным коммутаторам, обычно с 64 портами, для формирования еще более крупных кластеров. Половина из 64 портов листового коммутатора 800 Гбит/с подключена к 16 узлам, а оставшаяся половина — к магистральным коммутаторам.
В зависимости от размера кластера используется различное количество коммутаторов позвоночника. Intel предоставляет пример трех коммутаторов позвоночника, используемых для 32 подкластеров, состоящих из 512 узлов (4096 узлов Гауди). Intel утверждает, что эта конфигурация обеспечивает равную пропускную способность для всех соединений между серверами (неблокирующая «все ко всем»). Добавление еще одного уровня коммутаторов Ethernet может поддерживать до десятков тысяч ускорителей.
Производительность Gaudi 3 против Nvidia H100
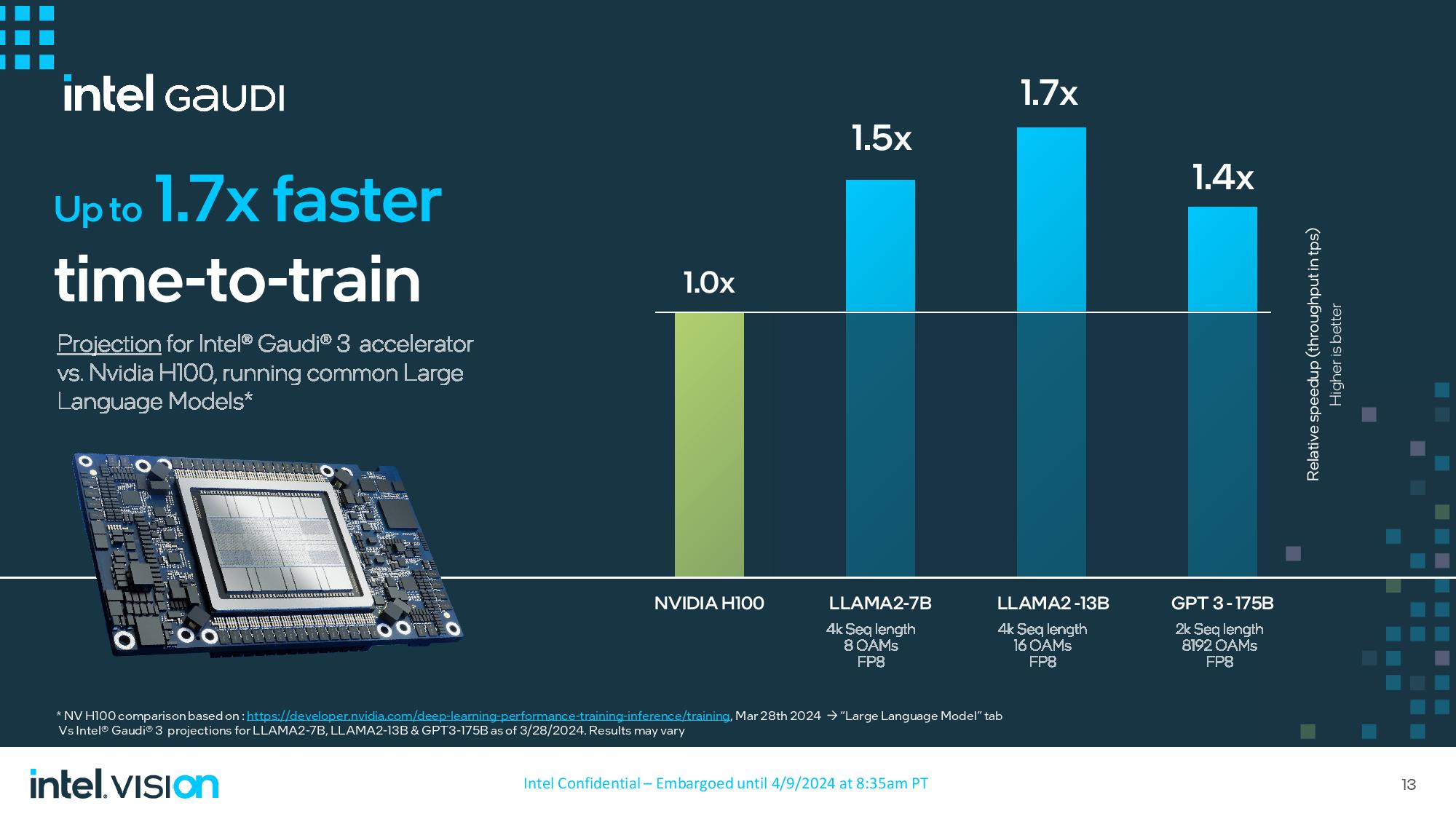
Intel поделилась прогнозами производительности для Gaudi 3, но, как и в случае со всеми тестами, предоставленными поставщиками, мы должны относиться к ним с долей скептицизма. Как вы увидите на последнем изображении в альбоме выше, Intel теперь просто предоставляет QR-код для информации о своих тестах вместо построчных подробностей тестовых конфигураций, которые она предоставляла раньше. Этот код не дает нам какого-либо осмысленного способа рассмотреть более подробные результаты этих тестов и конфигураций, поэтому добавьте немного соли к любому из этих заявлений о тестах.
Intel провела сравнение с общедоступными тестами для систем H100, но не провела сравнение с предстоящим Blackwell B200 от Nvidia из-за отсутствия сравнительных данных в реальном мире. Компания также не предоставила сравнения с многообещающими графическими процессорами AMD Instinct MI300 , но это невозможно, поскольку AMD продолжает избегать публикации публичных данных о производительности в принятых в отрасли тестах MLPerf.
Intel предоставила множество сравнений как в рабочих нагрузках обучения, так и в задачах вывода по сравнению с H100 с аналогичными размерами кластеров, но главный вывод заключается в том, что Intel утверждает, что Гауди в 1,5–1,7 раза быстрее в рабочих нагрузках обучения. Сравнения включают модели LLAMA2-7B (7 миллиардов параметров) и LLAMA2-13B с 8 и 16 ускорителями Гауди соответственно, а также модель GPT 3-175B, протестированную с 8192 ускорителями Гауди, все с использованием FP8. Интересно, что Intel не сравнивала здесь H200 от Nvidia, у которого объем памяти на 76% больше, а пропускная способность памяти на 43% больше, чем у H100.
Intel действительно сравнивала с H200 для своих выводов, но придерживалась производительности с одной картой, а не сравнивала производительность с масштабируемым масштабированием с кластерами. Здесь мы видим смешанную ситуацию: пять рабочих нагрузок LLAMA2-7B/70B оказываются на 10–20 % ниже, чем у графических процессоров H100, тогда как две соответствуют H200, а одна немного превосходит их. Intel утверждает, что производительность Gaudi лучше масштабируется при увеличении выходных последовательностей: Gaudi обеспечивает до 3,8 раз большую производительность с моделью Falcon со 180 миллиардами параметров и выходной длиной 2048.
Intel также заявляет о 2,6-кратном преимуществе в энергопотреблении для рабочих нагрузок вывода, что является важным фактором, учитывая ограничительные ограничения мощности в центрах обработки данных, но она не предоставила аналогичных тестов для учебных рабочих нагрузок. Для этих рабочих нагрузок Intel протестировала один H100 в общедоступном экземпляре и зарегистрировала энергопотребление H100 (по данным H100), но не предоставила примеров вывода с одним узлом или более крупными кластерами. Intel снова заявляет о более высокой производительности и, следовательно, эффективности при увеличении выходных последовательностей.
Экосистема программного обеспечения Гауди 3

Как показало доминирование Nvidia в области CUDA, экосистема программного обеспечения так же важна, как и аппаратное обеспечение. Intel рекламирует свой комплексный программный стек и заявляет, что «большинство» ее инженеров в настоящее время работают над усилением поддержки. В настоящее время Intel сосредоточена на поддержке мультимодальных моделей обучения и вывода, а также RAG (генерация с расширенным поиском).
В Hugging Face доступно более 600 000 контрольных точек моделей искусственного интеллекта, и Intel заявляет, что ее работа с Hugging Face, PyTorch, DeepSpeed и Mosaic упростила процесс портирования программного обеспечения, что позволило сократить сроки развертывания систем Gaudi 3. Intel утверждает, что большинство программистов программируют на уровне платформы или выше (т. е. просто используют PyTorch и пишут сценарии на Python), и что низкоуровневое программирование с использованием CUDA не так распространено, как кажется.
Инструменты Intel предназначены для упрощения процесса переноса, абстрагируя при этом основные сложности, при этом OneAPI служит базовым ядром и коммуникационными библиотеками. Эти библиотеки соответствуют спецификациям, изложенным Unified Accelerator Foundation (UXL) и отраслевым консорциумом, в который входят, среди прочего, Arm, Intel, Qualcomm и Samsung, которые призваны предоставить альтернативу CUDA. PyTorch 2.0 оптимизирован для использования OneAPI для вывода и обучения с использованием процессоров и графических процессоров Intel. Intel заявляет, что ее OpenVino также продолжает быстро внедряться: в этом году было скачано более миллиона загрузок.
Мысли
Как мы уже говорили выше, Intel, Nvidia и AMD идут разными путями к обеспечению улучшенной масштабируемости кластера, которая является ключом к производительности как в обучении искусственного интеллекта, так и в рабочих нагрузках вывода. У каждого подхода есть свои сильные стороны, но запатентованное NVLink от Nvidia является наиболее зрелым и хорошо зарекомендовавшим себя решением, а его распространение на стоечные архитектуры является значительным преимуществом. Тем не менее, подход Intel к сетям на основе Ethernet обеспечивает открытое решение, которое предоставляет множество возможностей настройки за счет поддержки сетевых коммутаторов от различных производителей, а встроенные сетевые карты также обеспечивают ценовые преимущества по сравнению с конкурирующей серией AMD Instinct MI300 .
Тем не менее, как продукты Nvidia на базе Grace, так и AMD MI300A предлагают сложные объединенные пакеты CPU+GPU, которые будет сложно превзойти в некоторых рабочих нагрузках, в то время как Intel продолжает полагаться на отдельные компоненты CPU и ускорителя из-за отмены объединенной версии CPU+GPU. из Фэлкон Шорс . Поступали сообщения о том, что новые серверы Nvidia GB200 CPU+GPU составляют основную часть заказов компании Blackwell, что подчеркивает ненасытный аппетит отрасли к этим типам тесно связанных продуктов.
Будущий продукт Intel Falcon Shores будет представлять собой конструкцию, основанную только на ускорителе искусственного интеллекта, поэтому он по-прежнему сможет конкурировать с кластерами Nvidia и AMD, оснащенными только графическими процессорами. Мы также видим место для обновленного поколения Gaudi 3, которое переходит от HBM2E к HBM3/E — и AMD, и Nvidia используют более быструю память в своих продуктах AI. Несмотря на то, что компания не предоставила точные данные, Intel заявляет, что также планирует агрессивно конкурировать по ценам, что может стать мощным рецептом, поскольку Nvidia продолжает бороться с дефицитом из-за падения спроса на ее графические процессоры.
Falcon Shores также будет совместим с кодом, оптимизированным для Гауди, что обеспечит совместимость вперед. Intel также приводит трехкратное улучшение своей платформы Gaudi 2 за последние несколько кварталов в качестве примера более широкого внедрения своей платформы.
Примечательно, что Intel не рекламировала свои графические процессоры Ponte Vecchio на этом мероприятии, что неудивительно, учитывая отмену графических процессоров следующего поколения Rialto Bridge , поэтому мы ожидаем, что усилия компании по искусственному интеллекту сосредоточатся исключительно на Gaudi 3, поскольку она готовит Falcon Shores. к запуску в следующем году.
Модели Gaudi 3 с воздушным охлаждением уже доступны партнерам и станут общедоступными в третьем квартале. Модели с жидкостным охлаждением появятся в четвертом квартале. Мы следим за веб-трансляцией Intel Vision для получения дополнительной информации и будем обновлять ее по мере необходимости.


0 Комментариев